Wan2.2-Fun-Inp is a start-end frame controlled video generation model launched by Alibaba PAI team. It supports inputting start and end frame images to generate intermediate transition videos, providing creators with greater creative control. The model is released under the Apache 2.0 license and supports commercial use. Key Features:Documentation Index
Fetch the complete documentation index at: https://dripart-mintlify-update-manual-install-from-readme-30640.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- Start-End Frame Control: Supports inputting start and end frame images to generate intermediate transition videos, enhancing video coherence and creative freedom
- High-Quality Video Generation: Based on the Wan2.2 architecture, outputs film-level quality videos
- Multi-Resolution Support: Supports generating videos at 512×512, 768×768, 1024×1024 and other resolutions to suit different scenarios
- 14B High-Performance Version: Model size exceeds 32GB, with better results but requires high VRAM
- 🤗Wan2.2-Fun-Inp-14B
- Code repository: VideoX-Fun
ComfyOrg Wan2.2 Fun InP & Control Youtube Live Stream Replay
Wan2.2 Fun Inp Start-End Frame Video Generation Workflow Example
This workflow provides two versions:- A version using Wan2.2-Lightning 4-step LoRA from lightx2v for accelerated video generation
- A fp8_scaled version without acceleration LoRA
| Model Type | VRAM Usage | First Generation Time | Second Generation Time |
|---|---|---|---|
| fp8_scaled | 83% | ≈ 524s | ≈ 520s |
| fp8_scaled + 4-step LoRA | 89% | ≈ 138s | ≈ 79s |
1. Download Workflow File
Please update your ComfyUI to the latest version, and find “Wan2.2 Fun Inp” under the menuWorkflow -> Browse Templates -> Video to load the workflow.
Or, after updating ComfyUI to the latest version, download the workflow below and drag it into ComfyUI to load.
Download JSON Workflow
Use the following materials as the start and end frames

2. Models
Diffusion Model- wan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
3. Workflow Guide
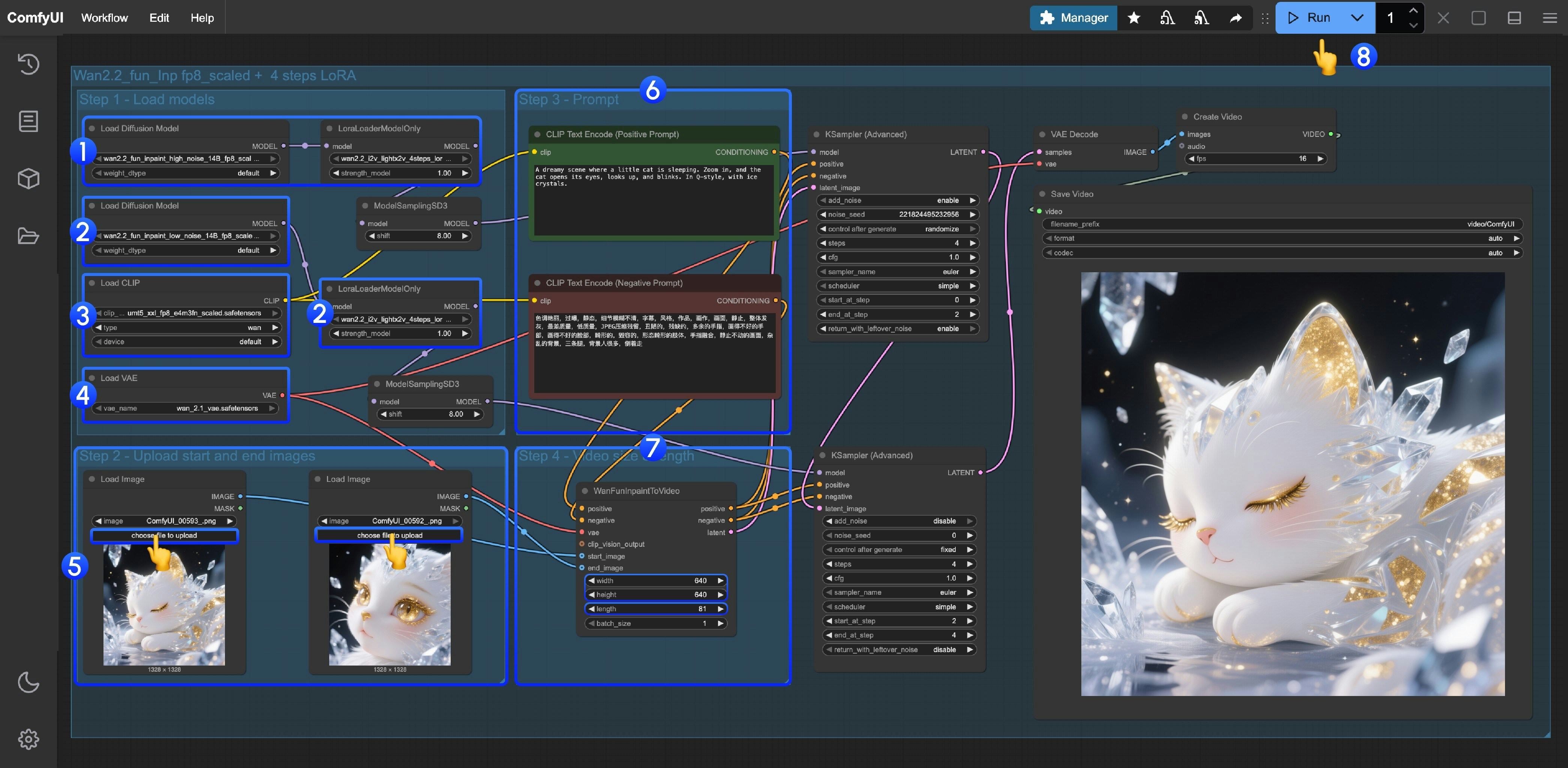
This workflow uses LoRA. Please make sure the corresponding Diffusion model and LoRA are matched.
- High noise model and LoRA loading
- Ensure the
Load Diffusion Modelnode loads thewan2.2_fun_inpaint_high_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
LoraLoaderModelOnlynode loads thewan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- Ensure the
- Low noise model and LoRA loading
- Ensure the
Load Diffusion Modelnode loads thewan2.2_fun_inpaint_low_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
LoraLoaderModelOnlynode loads thewan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
- Ensure the
- Ensure the
Load CLIPnode loads theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode loads thewan_2.1_vae.safetensorsmodel - Upload the start and end frame images as materials
- Enter your prompt in the Prompt group
- Adjust the size and video length in the
WanFunInpaintToVideonode- Adjust the
widthandheightparameters. The default is640. We set a smaller size, but you can modify it as needed. - Adjust the
length, which is the total number of frames. The current workflow fps is 16. For example, if you want to generate a 5-second video, you should set it to 5*16 = 80.
- Adjust the
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation